
Ar žinojai, kad yra viena klaida …
… kad tūkstančiai duomenų mokslo pradedančiųjų nesąmoningai įsipareigoja?
Ir kad ši klaida gali viena pati sugadinti jūsų mašininio mokymosi modelį?
Ne, tai nėra perdėta. Mes kalbame apie vieną iš kebliausių taikomojo mašininio mokymosi kliūčių: perteklinis.
Bet nesijaudinkite:
Šiame vadove paaiškinsime, ką tiksliai reiškia perpildymas, kaip jį pastebėti savo modeliuose ir ką daryti, jei jūsų modelis yra per didelis.
Pabaigoje sužinosite, kaip kartą ir visiems laikams spręsti šią keblią problemą.
Turinys
- Pertvarkymo pavyzdžiai
- Signalas ir triukšmas
- „Fit“ gerumas
- Pernelyg didelis ir netinkamas
- Kaip nustatyti perteklių
- Kaip išvengti perteklių
- Papildomi resursai
Pertvarkymo pavyzdžiai
Tarkime, kad mes norime numatyti, ar studentas nusileis darbo pokalbyje, remdamasis savo gyvenimo aprašymu.
Tarkime, kad mokome modelį iš duomenų rinkinio, kuriame yra 10 000 gyvenimo aprašymų ir jų rezultatų.
Tada mes išbandome modelį originaliame duomenų rinkinyje ir jis prognozuoja rezultatus 99% tikslumu … oho!
Bet dabar ateina blogos naujienos.
Kai paleidžiame modelį pagal naują („nematytą“) duomenų rinkinį, gauname tik 50% tikslumą … oh-oh!
Mūsų modelis to nedaro apibendrinti nuo mūsų mokymo duomenų iki nematytų duomenų.
Tai vadinama per dideliu pritaikymu, ir tai yra dažna mašininio mokymosi ir duomenų mokslo problema.
Tiesą sakant, perpildymas realiame pasaulyje vyksta visada. Norėdami išgirsti pavyzdžių, turite įjungti tik naujienų kanalą:

Perteklinė rinkimų pirmenybė (šaltinis: XKCD)
Signalas ir triukšmas
Galbūt girdėjote apie garsiąją Nate Silver knygą „Signalas ir triukšmas“.
Prognozuodami modeliavimą, galite galvoti apie „signalą“ kaip apie tikrąjį pagrindinį modelį, kurį norite sužinoti iš duomenų.
Kita vertus, „triukšmas“ nurodo nereikšmingą duomenų rinkinio informaciją ar atsitiktinumą.
Pvz., Tarkime, jūs modeliuojate vaikų ūgį ir amžių. Jei imtumėte didelę dalį gyventojų, rastumėte gana aiškų ryšį:

Ūgis ir amžius (šaltinis: CDC)
Tai yra signalas.
Tačiau jei galėtumėte atrinkti tik vieną vietinę mokyklą, santykiai gali būti drumstesni. Tam įtakos turėtų neįprasti (pvz., Vaikas, kurio tėtis yra NBA žaidėjas) ir atsitiktinumas (pvz., Vaikai, kurie brendimą pasiekė skirtingo amžiaus).
Triukšmas trukdo signalui.
Čia atsiranda mašininis mokymasis. Gerai veikiantis ML algoritmas atskirs signalą nuo triukšmo.
Jei algoritmas yra per daug sudėtingas arba lankstus (pvz., Jame yra per daug įvesties funkcijų arba jis nėra tinkamai sureguliuotas), jis gali „atminti triukšmą“, užuot radęs signalą.
Šis „overfit“ modelis leis prognozuoti pagal tą triukšmą. Ji neįprastai gerai atliks savo mokymo duomenis … tačiau labai prastai, naudodama naujus, nematytus duomenis.
„Fit“ gerumas
Statistikoje tinkamumo gerumas reiškia, kaip tiksliai prognozuojamos modelio vertės sutampa su pastebėtomis (tikrosiomis) vertėmis.
Modelis, kuris išmoko triukšmą, o ne signalą, laikomas „tinkamu“, nes jis tinka mokymo duomenų rinkiniui, tačiau prastai tinka naujiems duomenų rinkiniams.
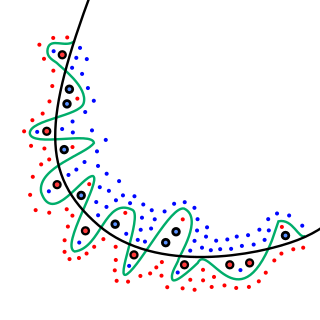
Nors juoda linija gerai tinka duomenims, žalia linija yra per didelė.
Pernelyg didelis ir netinkamas
Mes galime geriau suprasti perteklių, žiūrėdami į priešingą problemą, nepakankamai.
Nepakankamas atvejis atsiranda, kai modelis yra per paprastas – informuojamas per mažai funkcijų arba per daug sureguliuotas – dėl to jis yra nelankstus mokantis iš duomenų rinkinio.
Paprastų besimokančiųjų prognozės dažniausiai skiriasi, bet labiau linkę į neteisingus rezultatus (žr. „The Bias-Variance Tradeoff“).
Kita vertus, sudėtingų besimokančiųjų prognozės dažniausiai skiriasi.
Ir šališkumas, ir dispersija yra mašininio mokymosi prognozavimo klaidų formos.
Paprastai mes galime sumažinti klaidą dėl šališkumo, bet dėl to galime padidinti paklaidą dėl dispersijos arba atvirkščiai.
Šis kompromisas tarp pernelyg paprasto (didelio šališkumo) ir per sudėtingo (didelio dispersijos) yra pagrindinė statistikos ir mašininio mokymosi sąvoka, turinti įtakos visiems prižiūrimiems mokymosi algoritmams.

Šališkumas prieš dispersiją (šaltinis: EDS)
Kaip nustatyti perteklių
Pagrindinis iššūkis, susijęs su per dideliu pritaikymu ir apskritai su mašininiu mokymusi, yra tas, kad negalime žinoti, kaip gerai mūsų modelis veiks su naujais duomenimis, kol iš tikrųjų jų neišbandysime.
Norėdami tai išspręsti, pradinį duomenų rinkinį galime padalyti į atskirus mokymai ir testas pogrupiai.

Traukinio bandymo padalijimas
Šis metodas gali apytiksliai įvertinti, kaip gerai mūsų modelis veiks su naujais duomenimis.
Jei mūsų modeliui daug geriau sekasi treniruočių rinkinyje nei bandymų rinkinyje, tada mes greičiausiai perpildome.
Pavyzdžiui, tai būtų didelė raudona vėliava, jei mūsų modelis matytų 99% tikslumą treniruočių rinkinyje, bet tik 55% tikslumą bandymų rinkinyje.
Jei norite sužinoti, kaip tai veikia „Python“, turime pilną mašininio mokymosi naudojant „Scikit-Learn“ pamoką.
Kitas patarimas – pradėti nuo labai paprasto modelio, kuris būtų naudojamas kaip etalonas.
Tada, bandydami sudėtingesnius algoritmus, turėsite atskaitos tašką, kad sužinotumėte, ar verta papildomo sudėtingumo.
Tai „Occam“ skustuvo testas. Jei dviejų modelių našumas yra panašus, paprastai turėtumėte pasirinkti paprastesnį.
Kaip išvengti perteklių
Aptikti perteklių yra naudinga, tačiau tai neišsprendžia problemos. Laimei, turite keletą galimybių išbandyti.
Štai keli populiariausi pertvarkymo sprendimai:
Kryžminis patvirtinimas
Kryžminis patvirtinimas yra galinga prevencinė priemonė nuo per didelio aprūpinimo.
Idėja yra sumani: naudokite pradinius treniruočių duomenis, kad sugeneruotumėte keletą mini traukinio testo dalių. Norėdami suderinti savo modelį, naudokite šiuos skilimus.
Standartiniame k-kartų kryžminiame patvirtinime duomenis skaidome į k pogrupius, vadinamus klostėmis. Tada mes iteratyviai mokome algoritmą ant k-1 klostių, o likusį klostymą naudojame kaip testo rinkinį (vadinamą „laikymo klostėmis“).
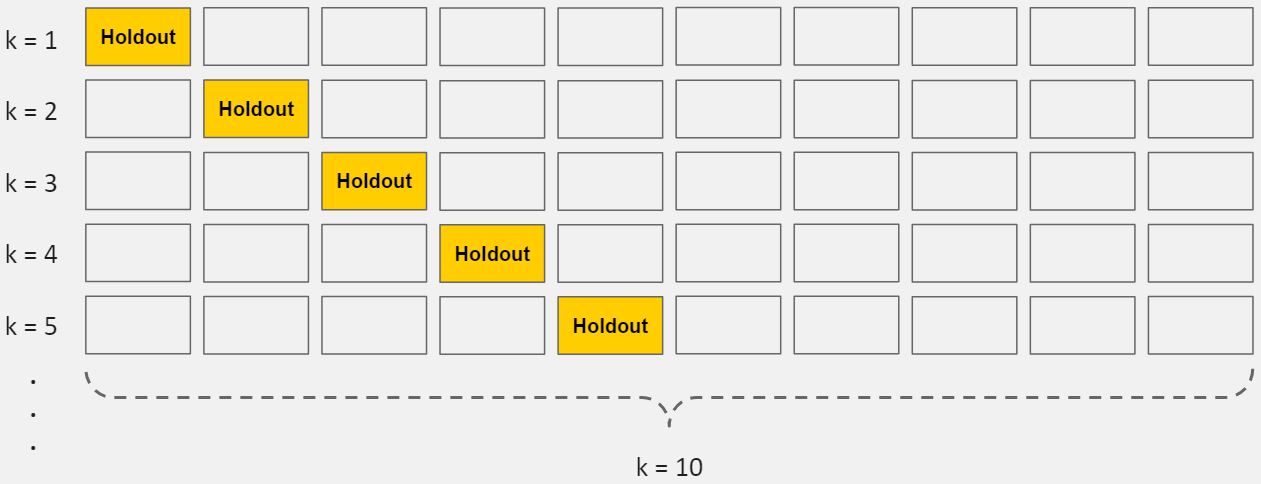
K-Fold kryžminis patvirtinimas
Kryžminis patvirtinimas leidžia suderinti hiperparametrus tik su originaliu treniruočių rinkiniu. Tai leidžia išsaugoti bandymų rinkinį kaip tikrai nematytą duomenų rinkinį, norint pasirinkti galutinį modelį.
Mes turime dar vieną straipsnį, kuriame pateikiama išsamesnė kryžminio patvirtinimo analizė.
Traukinys su daugiau duomenų
Kiekvieną kartą tai neveiks, tačiau mokymasis naudojant daugiau duomenų gali padėti algoritmams geriau aptikti signalą. Ankstesniame vaikų ūgio ir amžiaus modeliavimo pavyzdyje aišku, kaip atrankos daugiau mokyklų padės jūsų modeliui.
Žinoma, ne visada taip būna. Jei tiesiog pridėsime daugiau triukšmingų duomenų, ši technika nepadės. Štai kodėl visada turėtumėte užtikrinti, kad duomenys būtų švarūs ir tinkami.
Pašalinti funkcijas
Kai kuriuose algoritmuose yra integruotas funkcijų pasirinkimas.
Tiems, kurie to nedaro, galite rankiniu būdu pagerinti jų apibendrinamumą pašalindami nesusijusias įvesties funkcijas.
Įdomus būdas tai padaryti yra pasakoti istoriją apie tai, kaip kiekviena funkcija tinka modeliui. Tai panašu į duomenų mokslininko sukamą programinės įrangos inžinieriaus guminių ančių derinimo techniką, kai jie derina savo kodą, paaiškindami jį eilutėmis po eilutę guminei antiai.
Jei kas nors neturi prasmės arba sunku pagrįsti tam tikras ypatybes, tai yra geras būdas jas identifikuoti.
Be to, yra keletas funkcijų pasirinkimo euristinių parametrų, kuriuos galite naudoti geram atspirties taškui.
Ankstyvas sustojimas
Treniruodami mokymosi algoritmą iteratyviai, galite išmatuoti, kaip gerai veikia kiekviena modelio iteracija.
Iki tam tikro pasikartojimų skaičiaus naujos iteracijos patobulina modelį. Tačiau po to modelio gebėjimas apibendrinti gali susilpnėti, nes jis pradeda perpildyti treniruočių duomenis.
Ankstyvas sustojimas reiškia mokymo proceso sustabdymą, kol besimokantysis praeina tą tašką.
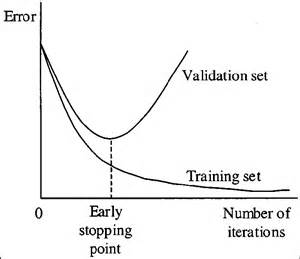
Šiandien ši technika dažniausiai naudojama gilinantis mokymuisi, o klasikiniam mašininiam mokymuisi pirmenybė teikiama kitoms technikoms (pvz., Reguliavimui).
Reguliavimas
Reguliavimas reiškia platų būdų dirbtinai priversti savo modelį būti paprastesnį.
Metodas priklausys nuo naudojamo besimokančiojo tipo. Pavyzdžiui, galite genėti sprendimų medį, naudoti iškraipymą neuroniniame tinkle arba pridėti baudos parametrą prie sąnaudų funkcijos regresijos būdu.
Dažnai reguliavimo metodas yra ir hiperparametras, o tai reiškia, kad jį galima sureguliuoti kryžminiu patvirtinimu.
Čia mes turime išsamesnę diskusiją apie algoritmus ir reguliavimo metodus.
Ansamblis
Ansambliai yra mašininio mokymosi metodai, skirti derinti kelių skirtingų modelių prognozes. Yra keli skirtingi ansamblio sudarymo metodai, tačiau dažniausiai naudojami du:
Maišavimas bandymai sumažinti galimybę per daug pritaikyti sudėtingus modelius.
- Tai lygiagrečiai rengia daug „stiprių“ besimokančiųjų.
- Stiprus besimokantysis yra gana nevaržomas modelis.
- Tada „bagging“ sujungia visus stiprius besimokančiuosius, kad „išlygintų“ jų prognozes.
Didinimas bandymai pagerinti paprastų modelių prognozuojamą lankstumą.
- Tai iš eilės moko daug „silpnų“ besimokančiųjų.
- Silpnas besimokantysis yra suvaržytas modelis (ty galite apriboti kiekvieno sprendimo medžio maksimalų gylį).
- Kiekvienas iš eilės sutelkia dėmesį į mokymąsi iš ankstesnio klaidų.
- Tada „Boosting“ sujungia visus silpnus besimokančiuosius į vieną stiprų besimokantįjį.
Nors maišai ir didinimas yra abu ansamblio metodai, jie problemą vertina priešingomis kryptimis.
„Bagging“ naudoja sudėtingus bazinius modelius ir bando „išlyginti“ jų prognozes, o „boost“ – paprastus bazinius modelius ir bando „sustiprinti“ jų bendrą sudėtingumą.
Tolesni žingsniai
Oi! Mes tik apėmėme nemažai sąvokų:
- Signalas, triukšmas ir kaip jie susiję su per dideliu įrengimu.
- Tinkamumas iš statistikos
- Nepakankamas ir per didelis
- Šališkumo ir dispersijos kompromisas
- Kaip nustatyti perteklių naudojant traukinio bandymo dalis
- Kaip išvengti perpildymo naudojant kryžminį patvirtinimą, funkcijų pasirinkimą, reguliavimą ir kt.
Tikimės, kad visų šių sąvokų susiejimas padėjo jas išaiškinti.
Norint iš tikrųjų įvaldyti šią temą, rekomenduojame įgyti praktinės praktikos.
Nors iš pradžių šios sąvokos gali atrodyti didžiulės, jos „spustelės į vietą“, kai tik pradėsite jas matyti realaus pasaulio kodekso ir problemų kontekste.
Taigi čia yra keletas papildomų išteklių, kurie padės jums pradėti:
Dabar eik ir mokykis! (Arba paprašykite, kad tai padarytų už jus!)